背景
數據非常的重要,歷史數據可以今我們分析目前的狀況,為之後的決策指明了方向,而實時數據則可以幫助我們在一些場景中獲得先機,譬如:監察購物降價通知。而我最近有個需求是想看看我的一些少數派文章的閱讀數,評論數和充電數,在一個地方就能看到數據,可以分析那個時段最多views,什麼類型的文章最符合大眾口味,所以就有了這篇文章。
成果展示
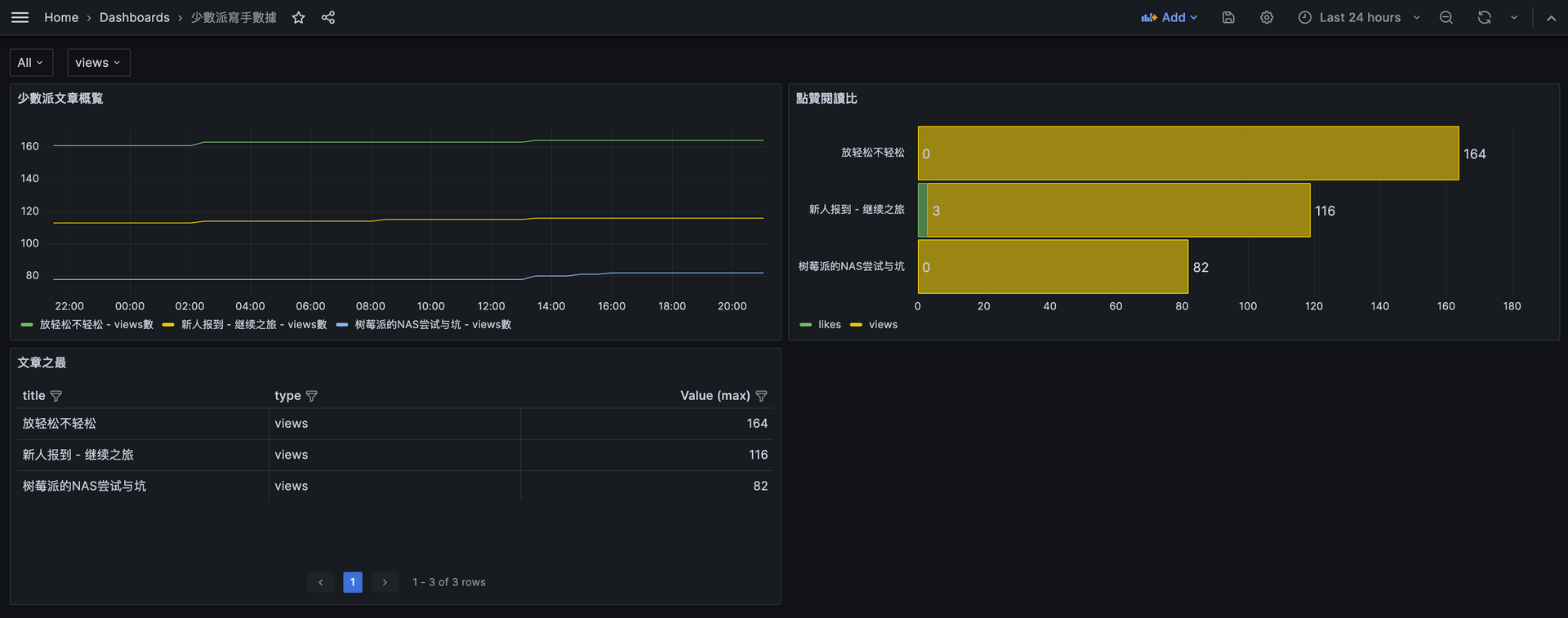
圖示說明:
- views, likes和comments時間折線圖:可以看到什麼時候閱讀量變化最大
- views和likes的堆疊柱狀圖:什麼題材更受觀眾歡迎
- 文章各項之最排行榜:同2的作用,但可以從views, likes和comments的面向看觀眾的喜好
前期工作
如何獲取少數派數據
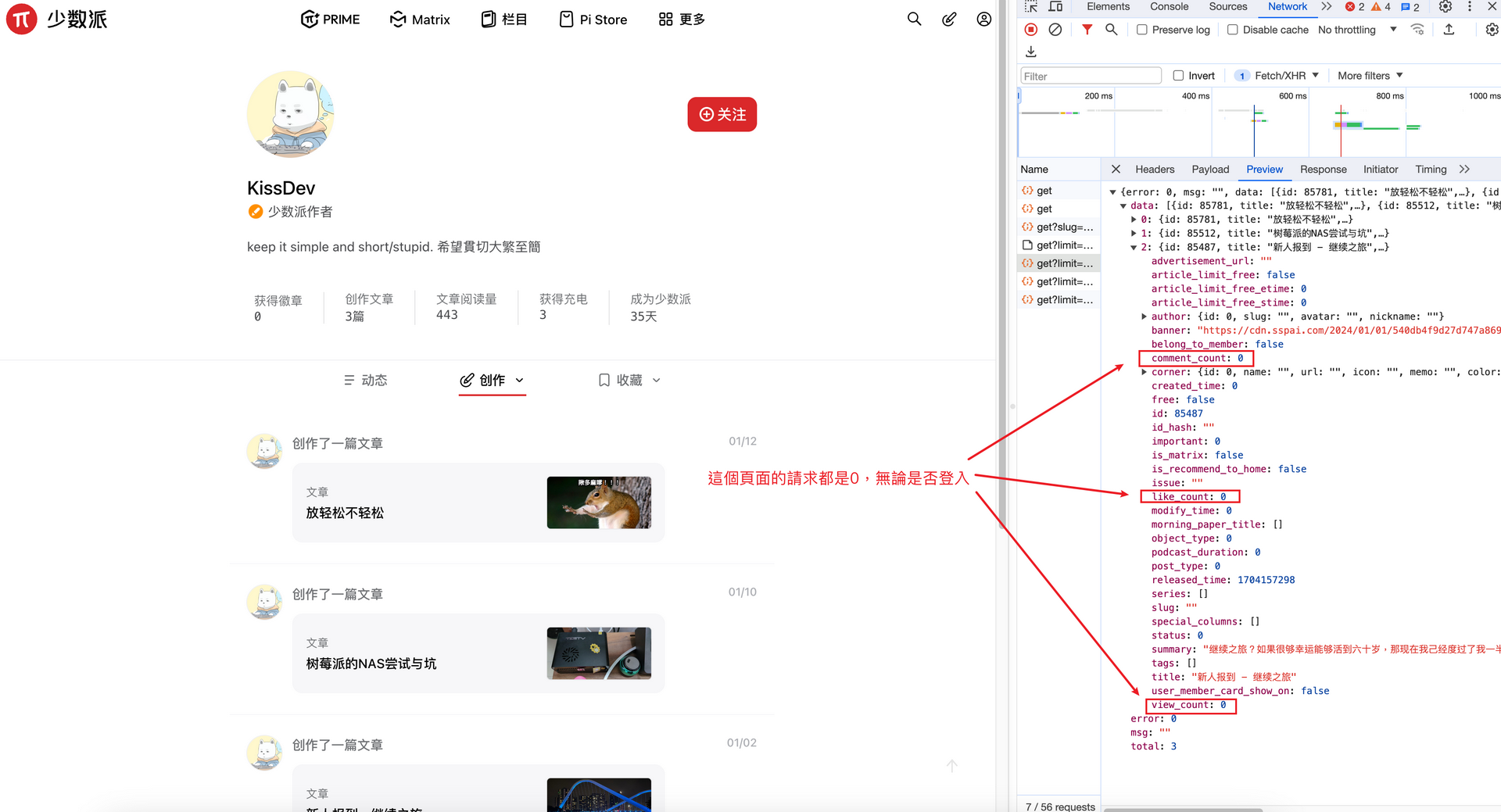
打開少數派的用戶頁面,F12開發者工具查看我的個人主頁,這個接口返回的數據就不正確都是0,應該是服務器沒有填充數據到模型。
但是在個人文章管理頁面的接口是可以返回正確的數據,如下圖所示:
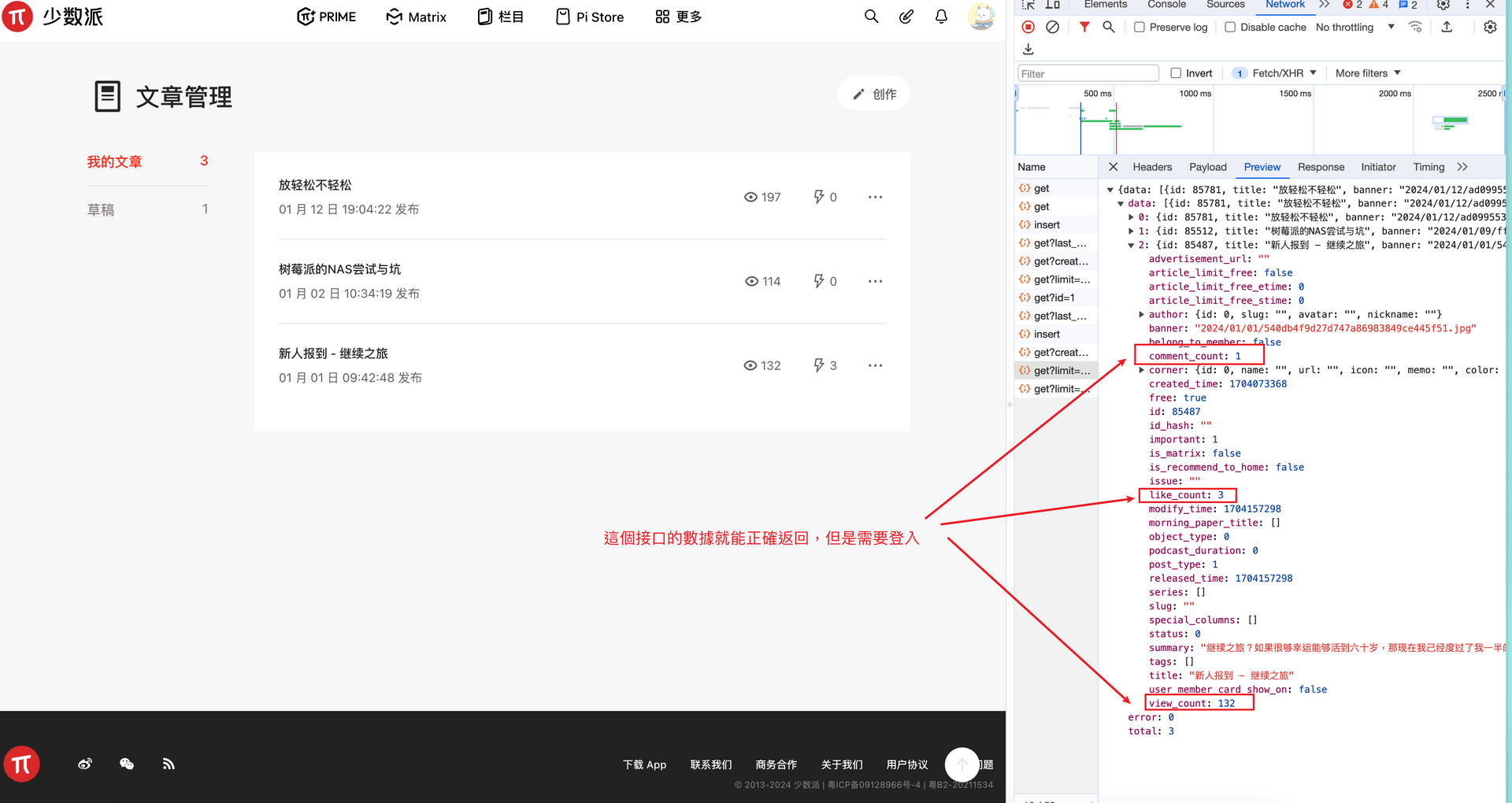
再查看一下相關的請求是只要帶JSON Web Token就可以了,然後查看了token的過期時間是一年,又因為登入是有驗證機制,自動化成本就變高了,以最簡單來實現就是拿登入之後的token來直接請求,設置一個提醒,到時過期再手動更換。源碼地址 在此
工作流
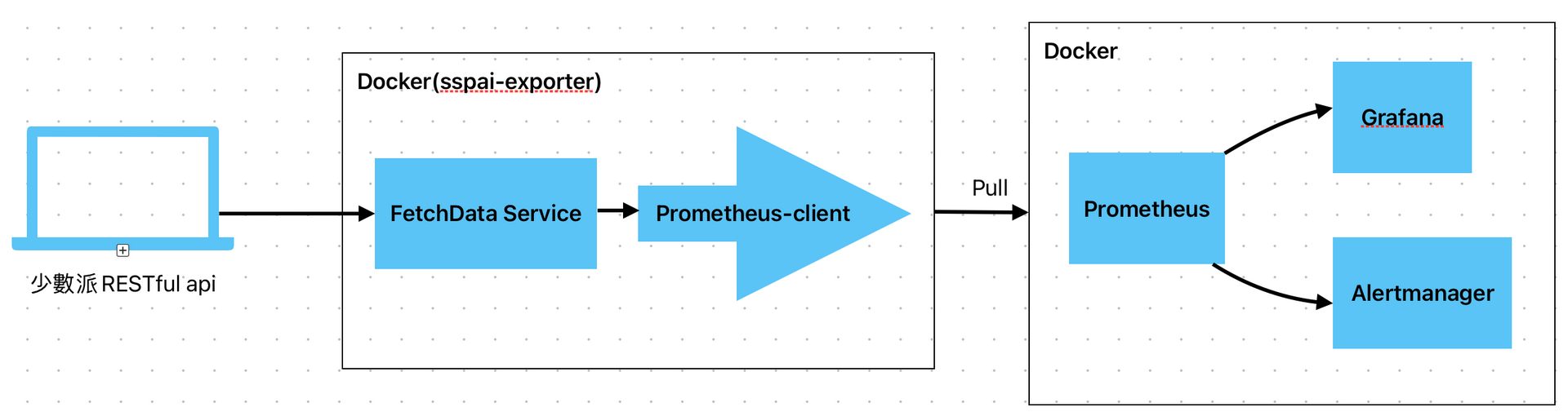
根據上個章節的說明,可得出如下圖所示:
創建一個sspai-exporter的容器服務,該工具定時地通過api抓取用戶的後台數據,由prometheus定時拉取,然後將數據展示到我的grafana中,可以以圖表的方式看到歷史數據的變化,並且在一些數據添加alert條件,譬如在文章達到一千次views的時候,發送通知我,但alertmanger沒有滿足我的要求,因為涉及到狀態的存儲,暫時先不管這部分需求,之後再想着怎麼處理。
目標受眾
- docker使用經驗
- yaml文件編寫經驗
- grafana + prometheus
部署
monitor套件
在你的服務器,NAS或本地電腦,建一個文件夾來存放相關配置文件docker-compose.yaml和prometheus.yaml。
docker-compose.yaml
其中docker-compose.yaml定義了各種服務的配署,內容如下:
version: '3'
# 可重用的log配置
x-common-log-conf: &common_log_conf
logging:
driver: json-file
options:
max-size: 10m
max-file: 3
services:
prometheus:
container_name: prometheus
image: prom/prometheus:latest
volumes:
- prometheus_data:/prometheus
- ./prometheus.yaml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
restart: unless-stopped
<<: *common_log_conf
grafana:
container_name: grafana
image: grafana/grafana-oss:latest
volumes:
- grafana_data:/var/lib/grafana
depends_on:
- prometheus
ports:
- "3000:3000"
restart: unless-stopped
<<: *common_log_conf
alertmanager:
container_name: alertmanager
image: prom/alertmanager:latest
ports:
- "9093:9093"
restart: unless-stopped
<<: *common_log_conf
sspai-exporter:
container_name: sspai-exporter
image: feimeizhan/sspai-prometheus-metrics:latest
environment:
# 用自己的token替換下面的值`${SSPAI_TOKEN}`
- SSPAI_TOKEN=${SSPAI_TOKEN}
ports:
- "4000:3000"
restart: unless-stopped
<<: *common_log_conf
volumes:
prometheus_data:
grafana_data:其中,sspai-exporter是上文提到的需要填寫自己的JWT即可。可以訪問一下http://localhost:4000/metrics查看最後是否有相應內容,看看是否抓取成功

prometheus.yaml
prometheus.yaml是prometheus的配置文件,可以用來配置拉取sspai-exporter的數據,具體內容如下,更多配置可參考官方文檔,其中需要注意的是,主動拉取的頻率不能太高,否則就會變成攻擊服務器了,控制的參數是scrape_interval,目前設置的是30分鐘拉取一次,測試的時候可以改成5s。
# my global config
global:
# scrape_interval: 1m # Set the scrape interval to every 15 seconds. Default is every 1 minute.
# evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: sspai-info
scrape_interval: 30m
static_configs:
- targets: ['sspai-exporter:3000']另外,如果修改了該配置文件之後要馬上生效,可以用這個方法:curl -X POST localhost:9090/-/reload
運行
配置完成之後,在該文件下使用命令docker-compose up -d。
配置grafana dashboard
打開剛部署成功的grafana管理後台,http://localhost:3000,然後導入我配置好的dashboard JSON,即可見到開篇所說的效果
如果是沒有數據的話,很可能是設署拉取的時間太長,可以將scrape_interval改成5s,上面的章節也有提及。
結語
其實本身的需求很簡單,根本都不需要用到prometheus這一套這麼重的工具,本來用TSDB和Chart.js就能搞好的,不過因為本身我自己的家用服務器就有了這一套工具,使用docker部署也最級方便,就有了這一篇文章了。
參考
- how to change legend
- Install Prometheus and Grafana on Kubernetes using Helm
- prometheus overview
- 為什麼使用類型
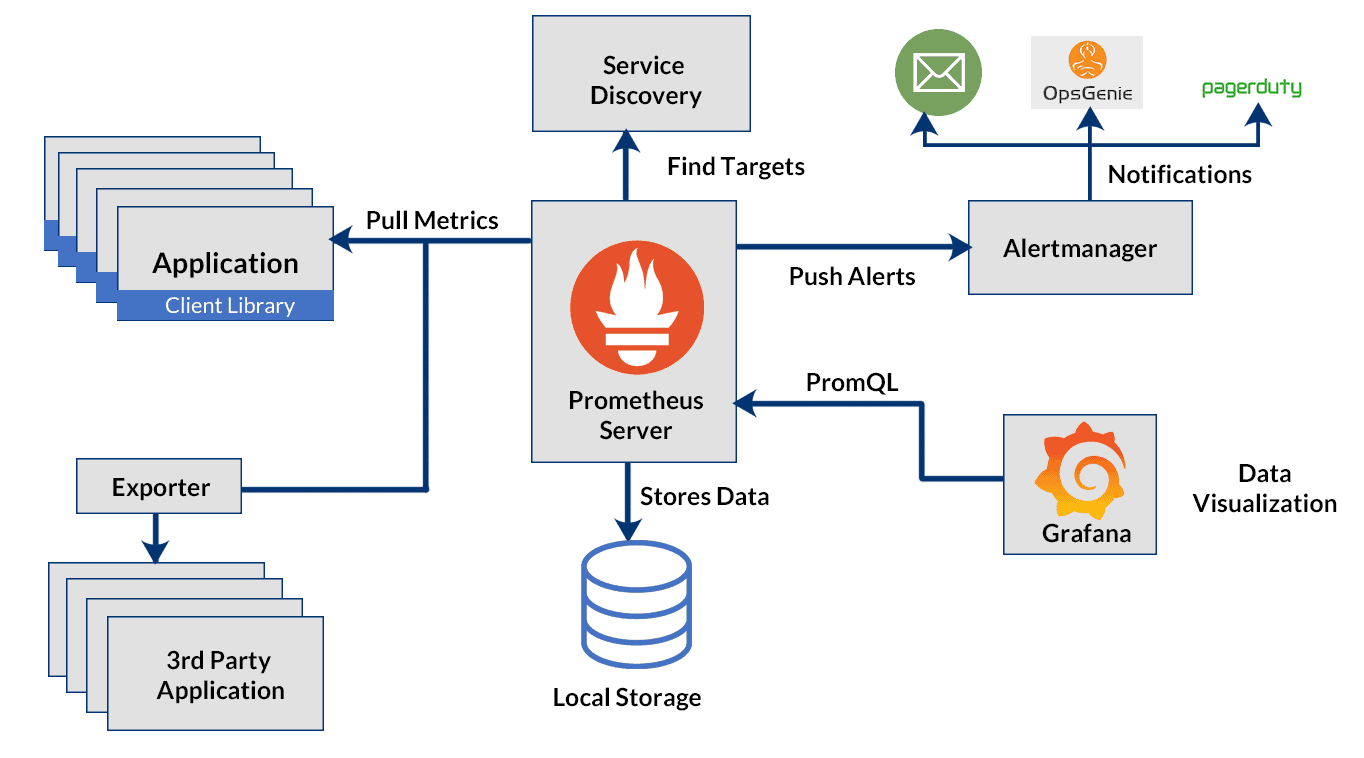
gauge而不使用counter-> 因為可能like也可能取消;簡單為主 metrics type - prometheus架構圖
{kind=link}